Involved tasks
FEDOT is currently capable of solving:
Pipeline building
FEDOT uses open-source library named GOLEM for optimization and learning of graph-based pipelines with meta-heuristic methods.
The library is potentially applicable to any graph-based optimization problem with clearly defined fitness function on it.
Sure enough, you may use your own custom optimization algorithms, see Automated Design of Pipelines.
Data preprocessing
FEDOT uses two types of preprocessing: obligatory and optional.
Note
Preprocessing is optional (see use_input_preprocessing main API parameter),
so you can save some time if your dataset (input data) is already preprocessed.
Obligatory preprocessing, as you might guess, solves major problems that can disrupt or complicate data processing, such as:
Problem |
Solution |
|---|---|
‘inf’ values in features |
replace |
huge amount of nans in features or targets |
drop |
binary categorical form of the features or targets |
binarize |
extra spaces in categorical features |
trim |
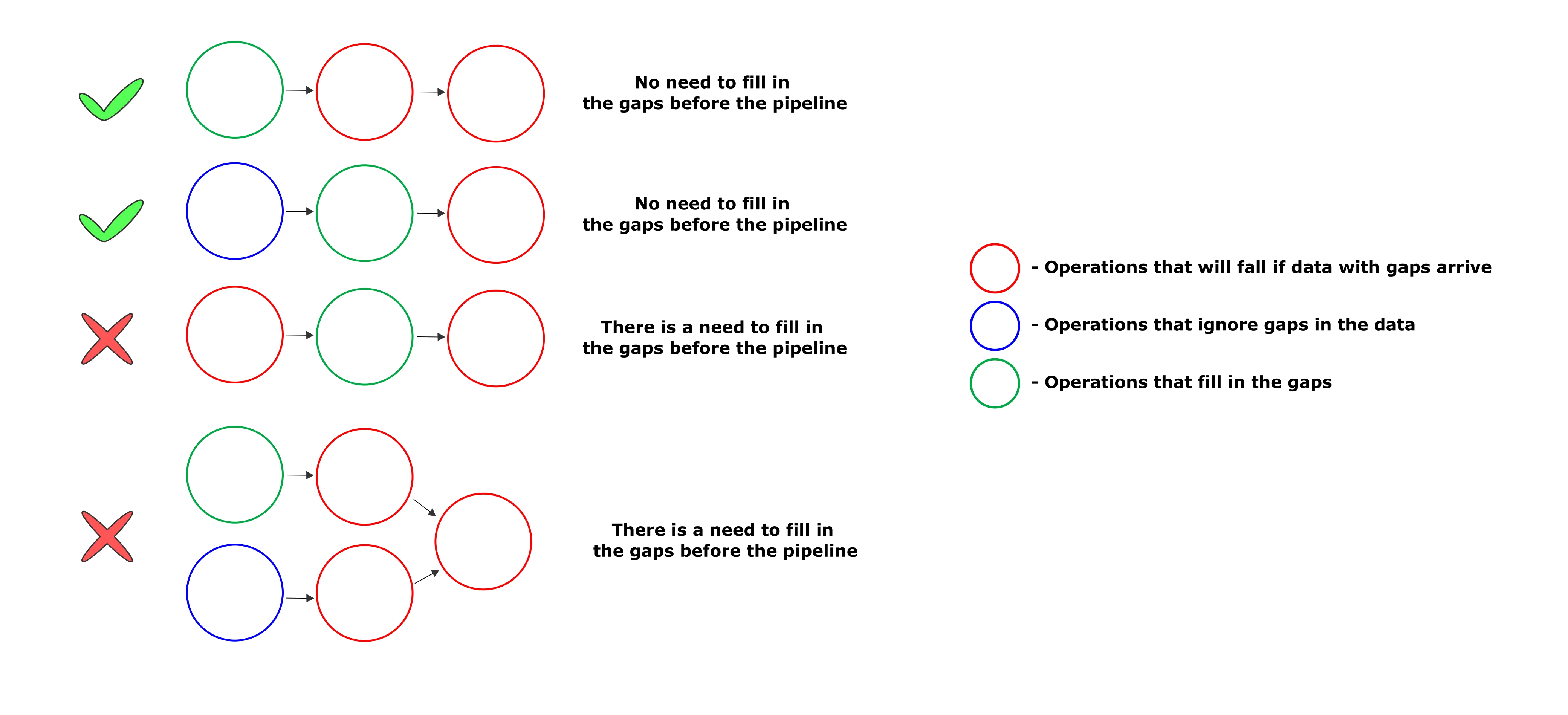
Optional preprocessing depends on a composed pipeline structure, and is applied only if it is necessary for a next model from a processing queue to work.
Problem |
Solution |
|---|---|
nans in features |
impute |
non-binary categorical features |
LabelEncode or OneHotEncode |
But depending on the pipeline structure, it might be ommited:
See also
Note
Both obligatory and optional preprocessing are applied only once.