Tabular Data Preprocessing
Main ideas about preprocessing
There are two preprocessing stages in FEDOT: on API and fit levels.
- Preprocessing on API level
On this level FEDOT determines what type of data was passed to the input and selects a strategy for reading data in according to the type.
Then recommendations are applied to the data. Recommendations applies only in safe_mode so if
safe_modeis True than FEDOT will cut large datasets to prevent memory overflow and use label encoder instead of OneHotEncoder if amount of unique values of categorical features is high.
- Preprocessing on fit level
Fit level can be divided into two stages: obligatory and optional.
On obligatory stage incorrect values are removed, extra spaces are cleaned, the types of values in the data are determined and, if there are several of them, then the data is converted to a single type. Also at this level, data columns are deleted if they could not be cast to the same type.
On optional stage gaps are filled in and categorical encoding applied if required.
NB: when it comes to predictions, the data type is no longer determined anew based on the passed ones. The data will be converted according to the type to which the training data was cast.
Architecture
The preprocessing architecture in FEDOT should also be considered separately at API and fit levels.
- API level
At this level,
ApiDataProcessoris responsible for issuing recommendations, andDataAnalyseris responsible for applying these recommendations to data.
- fit level
At fit level,
DataPreprocessoris responsible for applying obligatory and optional preprocessing to data.
General scheme of preprocessing
Preprocessing for tabular data in FEDOT can be represented as the following block diagram:
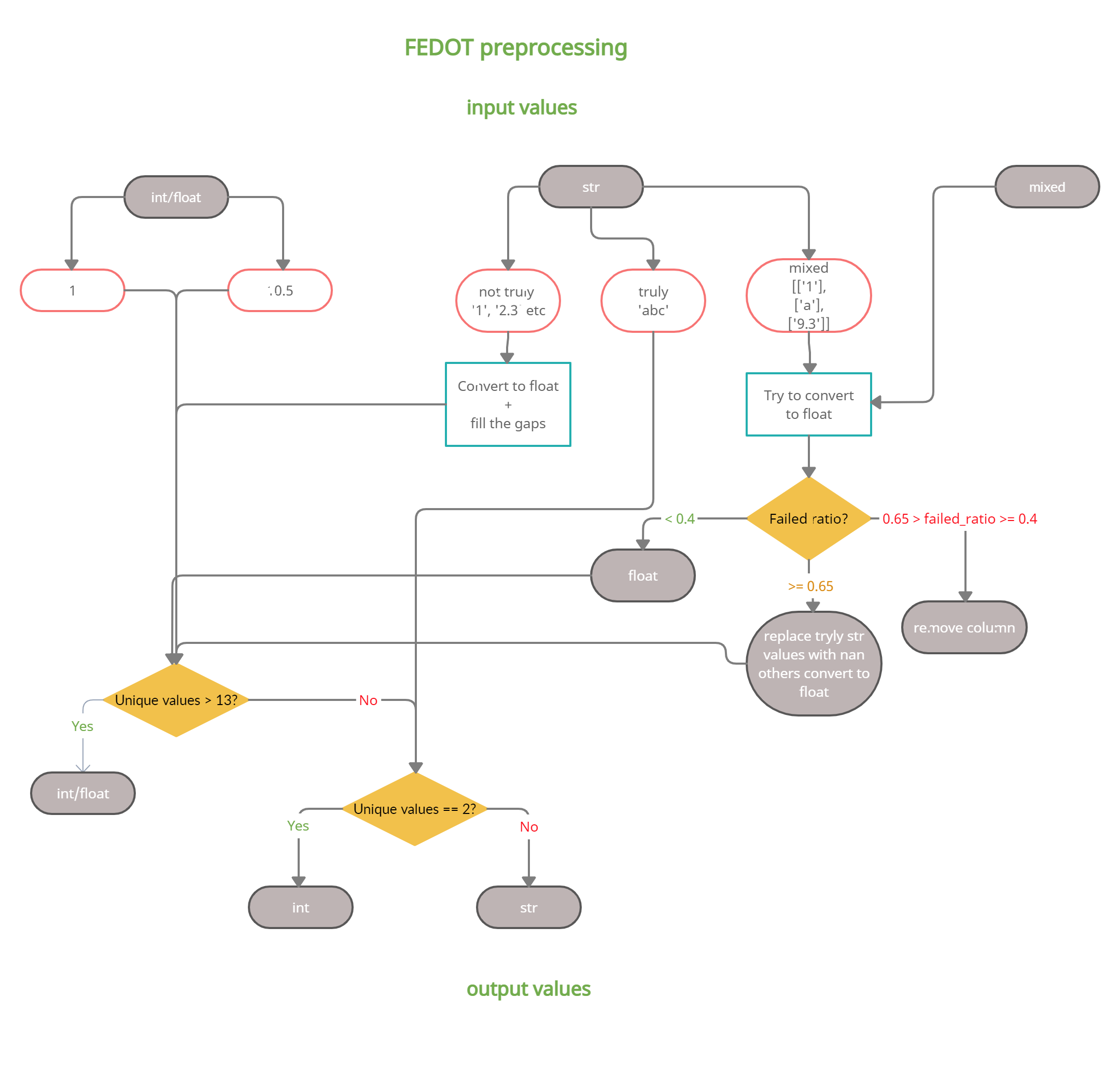
This preprocessing approach allows to get the real data type and minimize the number of dropped columns due to unrecognized data.
Examples of preprocessing
The processing of the following samples of data well demonstrates main important features of preprocessing in FEDOT.
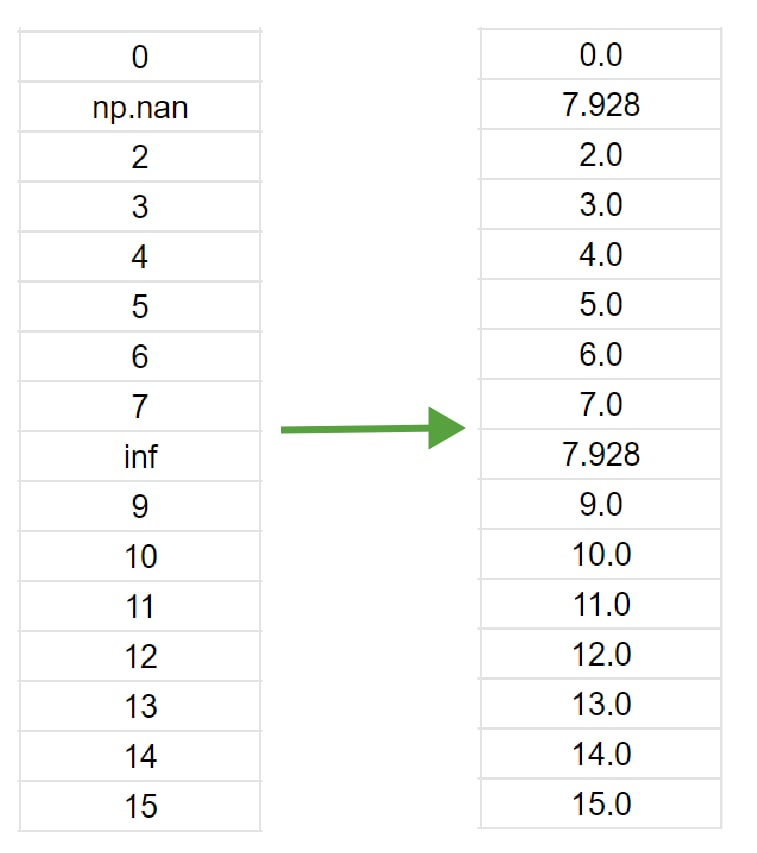
- gap filling:
The gaps are filled with the mean value. For categorical data – with the most frequent value along each column.
- column remove if too many nans:
If percent of nans is more than 90 than column will be removed.

- column revome if the data is too ambiguous:
In order to assess the possibility of converting data into one type, failed_ration calculated as unsuccessful_conversions/total attempts. If
0.65 > failed_ratio >= 0.4than column will be deleted.

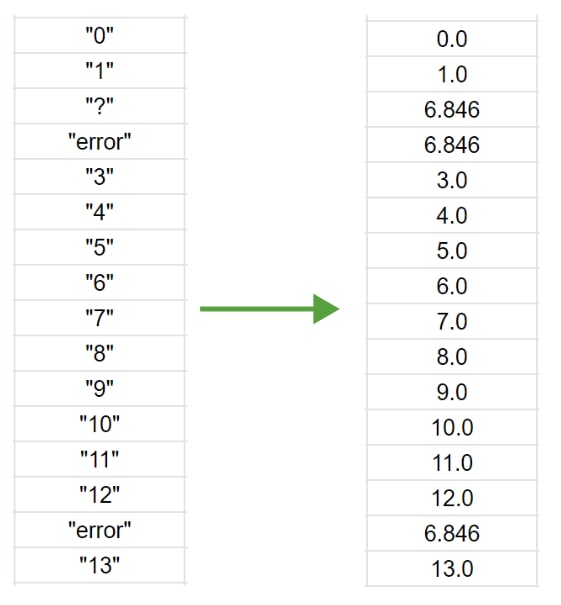
- cast to a single type:
- Cast to one type is done according to the block diagram:
true string removed and replaced with
np.nancolumn converted to
floatgaps filled in
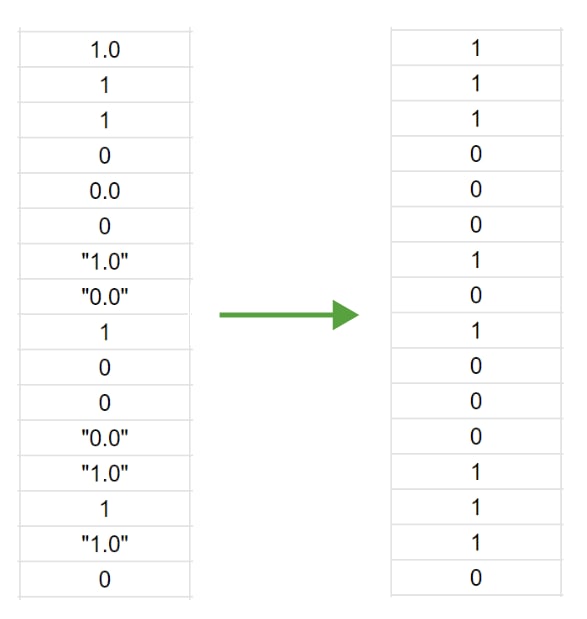
- reduction to a binary classification problem:
Due to the fact that the data is first converted to a numeric type, the string values are transformed and only two unique values obtained in the column.
Additional features
Also for more flexible approach to preprocessing there are 2 variables to control data conversion:
numerical_min_uniques– if number of unique values in the column lower, thannumerical_min_uniques- convert column into categorical. Default: 13
For example, converting column to numerical if the number of unique values is greater than 5:
# pipeline for which to set params
pipeline = Pipeline(PipelineNode('dt'))
pipeline = correct_preprocessing_params(pipeline, numerical_min_uniques=5)
After this preprocessing with this pipeline will be performed according to the specified conditions.